🚀 工具介绍
本页面的镜原甲骨智能输入法,为功能强大的甲骨文输入编辑器,实现了建立在镜原字库基础上的宽严式隶定自动匹配、辞典辞例补全、子字头替代补全、拼音输入法、部件输入法、悬浮链接跳转等功能,编辑器的具体设计基于 Microsoft 的monaco-editor,后者为主流代码编辑器vs-code的底层代码库,其设计初衷是为各种计算机编程语言的编辑提供强大的开源技术支持,主要功能包括代码语法高亮、类型提示、代码补全、文本折叠等功能,在编程界被相当广泛地所使用。本工具则在 monaco 的基础上进行了二次开发,将部分基础功能进行迁移和改进,以适应甲骨文学科中长久以来存在的输入难、字库字码设计与字形、音、义脱离的困难,实现了对甲骨文字的智能输入支持,目的是使得用户在编辑甲骨文时能够配合笔者制作的镜原甲骨全字库更加方便、快捷地输入文字,提高工作效率,并在此过程中达到巩固学习和认字能力,及熟悉甲骨文中所存在的复杂字形关系和释读成果。
目前编辑器的主要功能包括以下多个方面:
- 特殊符号触发的多功能辞条补全: 本工具目前提供了多种条件下的
辞条补全功能,可以在三种主要文本输入模式/状态下被激活:默认模式:这种模式即编辑器内正常打字输入时触发的效果。主要有两种,一种是宽严式隶定匹配,即输入文字后会自动根据后台数据库中预先定义好的严式和宽式隶定文字,通过{严}宽的方式进行补全,如正常输入“鼎”字后即会有鼎{貞}字样的提示,输入“惠”后会有叀{惠}的补全,目前已定义的常用匹配条数大概超过 1000 多组,能部分反映当前被学界所接受的一些主流隶定方法,毫无疑问,本编辑器的制作可以帮助节省许多查阅先前释文用例和寻找字码的时间。默认模式下的另一种效果是常用辞条补全,即输入文字后会自动匹配预先收录好的常用辞条,例如干支、词语等。如在编辑器内输入“癸”,则会自动出现“癸丑”、“癸亥”等干支的补全提示。这种模式下的输入效果主要是为一些常用词汇提供快捷访问,减少检字、打字的需要。@替代模式:这种模式由@符号触发,主要提供了同一字的不同写法的替代输入,替代字包括了不同“隶定”、以及“字头”、“子字头”的原形字,如输入@焚可得到“𤆰”、“”的子字头隶定提示,亦可得到“”、“”的甲骨原形字,这种模式能较好地适应不同考释成果带来的字头归并上的分歧,在存疑时可选择子字头进行显示,可以更精确地体现原拓字形的情况,并可以在未来数据库建设中提供到子字头等级上的录入和检索。而此模式下的另一种用法是@可触发拼音输入法,即可根据隶定拼音来查找原字,如在编辑器内输入@zhu即可得到“朱”字的字符,亦可得到“不 鼄”、及""(竹)字等原形字,再如输入@shu,可得到“”、“”、“𠅩”等字,而这是因为后者都隶属“孰”字的子级隶定法。当前编辑器环境下,只要某个隶定字处于 CJK 字符集内(包括拓展区),那么输入该字的拼音即可获得相应字码。单从这个角度来看,本编辑器即实现了传统意义上的甲骨文拼音输入法。%组字模式:这种模式由%符号触发,“%”代表文字切分,即可将一个字拆分为部件来进行输入。这种模式下的效果主要是可以根据部件构成式来过滤字形,即输入部件后就可以自动匹配预先定义好的部件组合,如编辑器内输入%日月即可得到“明”、“朝”等含有“日、月”部件的文字,或输入%人人人以得到“眾”字。这种模式下也就是传统意义上的部件输入法,其具体的输入效果也较上两种模式更为强大,尤其能够适应一些没有隶定、或不知读音、但却有着常用部件的复杂字形(也就是绝大多数甲骨字),普遍适用于各种独体、准独体及其他复合文字,配合着以上其他两种模式使用,基本能够解决目前已发现的所有甲骨文字的输入问题,同时逐渐熟悉此功能也能够帮助用户更好地理解甲骨文字的构字规律,提升学习效果。
这里再给出一些实用的补全用例:- @jian --->
翦 - @mian --->
黽 - @qu --->
齲 - %虍人 --->
- %木木刀 --->
- %鹿文 --->
- 翌 --->
翼{翌} - 惠 --->
叀{惠} - 牢 --->
𫳅{牢} - 遘 --->
冓{遘}雨 - 用 --->
𢆶{茲}用 - 余 --->
余一人
从一定程度上来看,以上三种模式分别对应了字库检索页面的隶定检索、拼音检索、部件检索功能,相当于在编辑器内置了的即时数据库检索功能。用户可以根据实际需要在这三种模式之间进行快速切换,并可配合字库检索页面的信息,以达到最佳的输入效果。当然具体的功能也需要根据实际的需求来进行熟悉和调整,欢迎广大师友根据实际体验提供反馈意见。
- 悬浮数据提示: 本编辑器在已有文字存在时,可尝试将鼠标悬浮至任一文字上方,编辑器会根据光标所在位置的文字内容,自动触发即时数据库检索,并显示后台返回的字形信息。同时,字形信息还提供了
悬浮链接跳转的功能,用户可以点击提示中蓝色的link字样,即可跳转到字库中专有字形页面,检查更多的字形和组类信息。这种功能配合网站其他页面,能够真正做到释文输入、释文检索和文字学习的无缝连接。但需要注意的是,当前此功能内置了一定延迟(~3s),以保证在快速输入时不会频繁触发,但这同时也会导致有时数据的正常显示可能会出现延迟较高的情况,故而在使用时需留意。此外,悬浮数据显示的触发也是由光标所在位置的具体文字内容来决定,如悬浮到的文字目前字库中没有收录相关字形数据,则不会返回任何信息。 - 文本高亮: 编辑器针对甲骨释文的一些规律对部分的文本模式进行了高亮显示,目前主要包括了
[...]补全内容、{...}宽式标注在内的几种简单的高亮效果,这些文本从原则上不属于原文的一部分,在原有静置状态下,与原文混在一起,有时不易区分,而从视觉上进行颜色显示,则更容易与甲骨主文本进行明显区别。此外,编辑器还有符号高亮的功能,这种功能可以被 Ctrl+F文本查找的功能所触发,即会高亮匹配到的文本,此外,亦可选择某一特定的文字和词语,再使用Ctrl+F2,Ctrl+F3的快捷键也可进行全部类似符号的快速高亮效果。 - 侧边栏粘贴: 编辑器左侧设置了侧边栏的组件,帮助提供字库中甲骨全部部件表及一些常用字的字码表,用户可以尝试点击相关按钮,编辑器即会做出反应并将选择的文字粘贴在编辑器中原光标所在的位置,并会触发相应的补全效果。这种功能在部分甲骨部件未有相关隶定、或本身较难输入时,能够提供更加快捷的字码支持。部件表的设计原则与字库页面的
部件检索相同,均采用黄天树先生最新的甲骨部首自然分类法,以“自然”到“人事”再到“物用”的顺序进行排列,具体的部件根据笔者在字库部件编码时根据实际字形情况做出少量的增删,进行少许熟悉后即可快速使用。 - 丰富的快捷键支持: 编辑器基于 monaco 原生库的支持,提供了非常丰富的按键组合,原则上与vscode keybindings相似,除了如 word 文档中常用的
Ctrl+F检索、Ctrl+Z撤销、Ctrl+Y重做等,还提供了一些特殊快捷键的支持,如Alt+↑或Alt+↓进行快速文本换行、Ctrl+Shift+K删除当前文本行、Ctrl+Shift+↑复制当前文本行等。除此之外的更多的快捷键可以用Ctrl+Shift+P来触发命令面板来查看,熟悉这些快捷键的使用能够大大提高输入效率,来解放频繁的鼠标操作。未来如有需要,编辑器也可以提供更多定制化的快捷键设置。 - 自动匹配和关闭括号: 作为常用代码编辑器中非常受欢迎的一项功能,本编辑器也迁移和集成了括号和引号自动匹配和关闭的功能,比如输入各种圆括号、方括号、引号等符号时,只需要输入其中一个符号(左部符号),编辑器会自动匹配和补全另一个括号,这个小功能虽然看似简单,但在长期保持输入的状态下,能够大大提升输入效率。目前支持的
括号匹配的符号包括{}、[]、【】、()、()、<>、""、''、“”、‘’等等。
除了以上提到的多种强大的功能支持,当前主流代码编辑器如 vscode、vim、atom 等经过多年的开发和完善,还有较此更多的隐藏使用方法(如代码格式化、代码折叠、代码片段、AI 编程助手等),再加上编程界庞大社区的力量和支持,各种丰富的插件和使用方式亦层出不穷,为多种语言的代码编写提供了非常好的写作体验。而作为底层开源项目的 Monaco editor 虽然相对 vscode 等高级功能和插件较少,但因为其 low-level 设计的原则,api 接口的设计具有相当的普适性,其对语言本身的规则并没有任何认知上的预设(所以无论是编程语言还是自然语言,从本质上并无任何区别),开发人员可以根据其文档的说明来适应自己语言的应用需求。从这种意义来说,将代码编辑器的原理移植到汉语语言,尤其是古文字的文字编辑上,其实也是一种非常合理的方法,属于跨学科的成果利用。使用甲骨文字库-数据库-编辑器三位一体的架构和耦合,可以说能够完全解决多年以来甲骨面临的打字“贴图”的问题,也可纠正当前过度聚焦于单一文字输入法研发的方向。因为从效果来看,无论是拼音输入法、部件输入法还是笔画输入法(当然笔画组合未来亦可集成至本编辑器内),都只能解决一部分甲骨文字输入的问题,其实用性最终不如动态的网络应用。当然,本次甲骨编辑工具的开发由于发布时间的限制和本人平时博士论文相关的各种相关工作,也仅仅探索了其领域的冰山一角,目前工具的主要研发目的只是为了支持字库字码输入而设计的,所以也没有加入太多与字码无关的功能。而且,最终个人收集数据的成本和力量也是十分有限的,所以当前能做到的也只是以输入辅助为主的编辑功能。但未来依靠社区的力量,当有潜力陆续引入文本挖掘、文本聚类、可视化、甚至于 AI 支持的内置文本分析功能。基于前端编程的强大技术支持,这些功能的实现并不是难事,只是需要时间和精力的投入。
✨ 使用技巧
本工具的设计本着简明易用的原则,但在实际输入时,仍有一些需要注意的地方,主要包括以下几个方面:
注意繁简有别: 当前甲骨学释读方面倾向根据文字构形进行专属隶定,故而隶定字中有繁有简、繁简混用,从而导致有时在文档里制作甲骨释文并不流畅。鉴于此,本工具"@替换"模式内置了繁简体的快捷转换,如输入@马即可得到“馬”字、输入@贞可得到“貞”的字符,这样有效避免了基于输入法工具的繁简模式的频繁切换,可以保持一种输入模式相对的连续使用。但是,需注意工具默认输入模式下的宽严式自动匹配,还是严格保持了繁简有别的原则,以与学界通行的隶定方法达成统一,故而如果遇到某些文字无法触发匹配,可先检查字符是否符合触发原则,如输入简体的“灾”,则无法触发“巛{災}”的补全,只会有灾{烖}的补全选择,这是因为两者对应的甲骨文字不是同一个,故而本工具在数据标注的时候也进行了不同的处理,这一点在使用时需要留意。
注意子字头写法有别的部件公式: 当前%组字模式主要负责根据部件返回直接相关的“字头”或“子字头”,原则上并不包括同一字的不同写法。这会导致在某些情况下,使用特定组合返回的仅是“子字头”的字码,而看不到“字头”字码。或者有时已知某字的一种特殊写法,但因为在字库中等级划为了“子字头”,输入相关部件时无法查找到该形,如彘字“”的写法,使用%矢豕并不能直接获得该字样,而只能得到“彘”字本身(“字头”级别)。这是因为部分子字头具有跟父级字头(如“”与“”)有着相同的部件构字式,只是空间位置或关系有别,故而不进行单独编码,以节省数据库空间和编辑器内存的使用。当然在理想情况下,部件构成返回结果似乎可以根据字头-子字头的内部关系来添加不同子字头,其具体实现也不困难,但需考虑到甲骨整体文字及异体数量众多的现状,况且很多甲骨部件的出现也十分频繁,如用%日字部件查找会返回数百例结果(“字头”),如亦包括同一字不同写法则会导致返回结果超过上千条,这样则违背了%组字模式过滤无关字形的初衷。
多使用常用字触发: 甲骨学中存在着各种各样有着复杂结构的严式隶定字,如果执着于直接寻找和组字这些文字,可能结果并不理想。但同一时间,很多复杂文字通常都有着为现代汉语中所常用的宽式隶定方法,如“𢦏{災}”、“{害}”、“灾{烖}”、“𦎫{敦}”等均含有至少一个常用隶定,而无论输入哪个隶定,在@模式下都可以触发自动补全。故而有碰到有不确定如何输入的复杂文字时,可考虑是否有可替代的写法进行自动补全,这样可以加快复杂文本的输入。
多模式混用: 当前工具的三种输入模式从设计上是各堪其职的,其职责界限十分分明。默认模式下仅提供宽严式匹配、常用辞条补全两种功能,且保证这方面严格遵守甲骨释文的通用规则,以便于制作准确的甲骨释文。@替代模式提供的是快捷拼音输入及同一字的不同写法(包括隶定和甲骨原形)的替换输入,这方面并不遵守任何规则,只是为了方便寻找正确文字,其范围较为广泛。而%组字模式是为了提供基于部件的强大过滤和检索,其范围涵盖所有甲骨字符的准确查找,从精度上来讲要比其他模式要更高。故而了解几种模式的区别,碰到比较复杂的难检字时,有拼音的可按拼音法,含有常用部件可用组字法,最后使用隶定触发释文和辞条补全。
📝 文本复制问题
虽然本页面的甲骨编辑器以字符作为绝对基础,能够很好地适应各种复杂的甲骨隶定和原形字的显示,用户可以选择编辑器正下方的字体选择框来动态切换隶定字体和甲骨字体,但这也仅限于编辑器和本网站的其他相似页面。如离开这些页面自带的系统,比如复制文本到本地 word 或 excel 当中,甲骨的文本显示仍将是一个很大的问题。为了能很好地显示这些复杂的字形(从字码上来看,这些字形涵盖了标准 CJK、CJK Extension A-I、BMP、PUA-A、PUA-B 等 Unicode 平面),网站实际上内置了“镜原甲骨字库”、“引得市 seal”、“HanaMinA”、“HanaMinB”、“KaiXinSongB”等多种字体,码点上大家各有分工,各负责解决一批字形的正确显示,从而保持网站应用对甲骨文字及其隶定字的支持。
但需注意的是,以上这些字体中的任何一个,要么属于商业字体,要么属于私人研究成果,都不含在一般计算机系统的默认字体内,故而在复制到本地文件中时,仍会不可避免地出现乱码、缺字、其他字体替代等问题。想要合理解决这些问题,还需要一些额外的设置。我们以 word 为例,如果想要在文档写作中显示甲骨的隶定和原形字,至少要经历以下几个操作环节:
- 下载和安装相应字体。 这一点在字体下载页面已有说明,用户可以根据自己的需求下载相应的字体,然后安装到本地系统中。如想显示全部字形,则除甲骨文字体外,以上提到的隶定字体均需下载安装。注意安装后,需要关闭 word 并重新打开,以使得新字体生效(无需重启计算机)。
- 复制编辑器内文本到 word。 本编辑器是一个纯文本编辑器,不含有任何文字样式和图片,故而在复制时,在粘贴到 word 或 excel 中时只会复制文本内容,不会带有原始字体设置,故而还需要进下一步的操作。
- 逐步选择正确字体。 主要取决于显示的文字类型,如需要
原形优先,即希望以甲骨的原形字来显示相关文本,则处理较为简单,使用本站提供的镜原甲骨字库即可,本字库使用多码点对应的方式,与汉字常用字有码点映射,故直接选择要显示的文本,替换为Oracular字体即可全部正常显示。但如果为隶定优先,即主要使用隶定显示文字,没有隶定的再以甲骨原形显示,则处理上较为复杂,这需要我们先从基础字体选起,先选择英文字体,如Times New Roman以保证英文和数字的美观(英文字体不重要的话也可以略过),其次选择基础中文字体,如使用宋体来显示常用汉字,之后选择隶定字符集,如seal(seal 字体优先,因为某些原因,seal 会被识别为英文字体)、HanaMinA、B等,这样仅会留下一些乱码的字形,通常以□、�、镜原甲骨字库专有的字形,这时需要为每一个文字逐个选择Oracular(注意不能全部替换,否则又会全部转换为原形字),这样之后才能够复现出编辑器的原有效果。这种方式的优点是可以根据实际需要选择不同的字体,但缺点是操作较为繁琐,且在大量文本替换时会比较耗时。
从整体来看,在没有标准 unicode 支持下的甲骨字码及隶定字码的显示还是具有相当的复杂性。一般 office 工具如 Mircosoft word,、excel、pdf 或 WPS word 等可以直接使用上部菜单栏中字体选择的方式来改变文档显示的字体类型,这种方式的优点当然是操作起来简单易明,但同时不合理的字体替换机制设计也会导致在需要使用多种字体显示相同码点时操作十分多余,而且后期批量修改字体时会取消原有选择好的特定字体,也不方便出版商和期刊编辑进行排版统一,这是 office 工具本身设计的缺陷。而比较而言,其他专业的文本排版工具如 markdown, latex 等则使用基于html或xml格式的标签来定义字体类型和样式,则合理较多。这些工具通常仅需要在文章开始定义一次所需字体即可,且可随时修改,其排版能力其实远大于 word 等应用,但这些工具使用起来门槛较高,当前来看不具有普遍的应用可能。不过熟悉该文件类型等师友,可以考虑使用以下方式。
如在Markdown类型文件中(推荐使用支持 html 样式的编辑器如Obsidian),在隶定优先的情况使用以下代码可以定义字体:
<span style="font-family: 'Times New Roman', '宋体', 'seal', 'HanaMinA', 'HanaMinB', 'KaiXinSongB', 'Oracular';">
在此输入甲骨文字
</span>
而如果是原形优先,则需要调整字体优先顺序:
<span style="font-family: 'Oracular', 'Times New Roman', '宋体', 'seal', 'HanaMinA', 'HanaMinB', 'KaiXinSongB';">
在此输入甲骨文字
</span>
使用以上设置就可以实现复杂的显示效果,这种其实依靠的是字体fallback机制,即在当前字体无法显示时,会自动调用下一个字体来显示,这样就可以实现多种字体的混合显示。本编辑器的设计其实也是充分利用了这种机制。在第一种隶定优先情况下,“Times New Roman”显示完所有英文字符,不能显示的任何中文字符,就会调用“宋体”,“宋体”只能显示基本 CJK,那么拓展区和 BMP 区域就依次尝试使用“seal”、“Hana”等来占用,而“seal”、“Hana”等字体都没有使用的 PUA 区域,镜原字库就充分利用了起来,用来显示剩下的字符。而在第二种原形优先的情况下,情况其实也是类似的。但以 PUA 区域为主的镜原字库能够显示基本 CJK 是因为本字库多码点的设计模式,即一个字同时会有来自 CJK 和 PUA 区域的两种码点对应,如果定义在第一位,就会优先以本字体显示,这个是字库在设计初始,就需要考虑到的一个重要环节,一定程度上避免了使用外部码点映射表的需要。
总的来看,甲骨文字的输入多年以来就是一个极难攻克的问题,就算是放在当前技术手段下,加上各种编程手段的加持,也不具有完全解决的可能性。这其中一个很大原因当然是没有统一 Unicode 方案进行字码支持,而甲骨文长久以来都不存在有被收录入 Unicode 的可能,其本质原因还是学界对于甲骨字头的分合问题、编码规则、字形规范和输入方式上没有统一的认知,而相关字体的制作也存在无法绕开的成本和知识门槛的问题。而字体和字码则是一体两面的现实,没有字体支持的字码就是计算机里的一个数字而已,就算分配到了 unicode,也不存在使用的意义。而没有字码标准的字体,具体的字符分配最终来看也是相当不稳定的,会随着时间变化或字体提供商的不同而有所差异,而不能被公众所共用。故而当前甲骨字形显示困难的问题,其实是有着多方面不可控的因素的,也不是一个简单字库或输入法就能解决的。同样的也适用于金文和战国文字等体系,最终还是要靠学术研究成果的积累和相关技术支持才有解决的希望。
⚠️ 已知问题
当前工具在开发测试过程中,在 monaco 的基础上修正了原生 api 中未能处理的一些实用情况,目前能很好地适应正常输入模式、粘贴模式、侧边栏文字添加及少数鼠标移动模式下的文本触发提示,但需注意有以下几种输入情况可能未有理想的效果:
- 颠倒的符号顺序无法触发。 在“@”、“%”的特殊输入模式下,正确触发的文本模式为
@文字或%组件,即需确保@、%出现在要替换文本的之前,并尽量在同一行内定义。如先输入文本,再移动鼠标在文字前方加入@、%等触发符号,提示则无法出现。这是因为当前程序的编码逻辑为提取光标所在前方的文本内容作为实际检测文字,其后方的文本会自动忽略。 - 存在多个相同符号时无法触发。 在“@”、“%”模式下,编辑器中同一行中有且只能有一个“@”或“%”存在,如果存在多个“@”,则无法正常触发,故而编辑时尽量确保删除冗余的触发符号。
- 不同输入模式无法构成连续触发。 从“@”、“%”特殊模式中接受的文本提示会正常替代原有文本,但作为新出现的文本,一般不会再次触发默认模式下的文本提示。这是 monaco 原生 api 的默认行为,本程序开发时亦未做出修改,目的是为了避免过于复杂的逻辑以及递归循环(否则部件触发单字,单字触发宽严匹配,宽严匹配触发辞条,辞条触发句例,句例触发段落会导致触发效果边界不明,造成可能的内存溢出及滥用)。故使用时如有实际需要,可使用复制粘贴新文字的方式手动进行触发。
- 少数非 CJK 字符部件无法触发部件公式: 这种情况包括“”、“”、“”等字,虽然这些字如“”有可识读的“𡆥”、“犬”的部件,数据库中也的确进行了相应的编码,但使用
%𡆥犬仍无法获得“”字。这是因为类如“𡆥”、“”等非基本 CJK 字集的集外字虽然渲染时为单个文字,但其实际占用字符为 2 位,这类字符在 unicode 中被称为“surrogate pairs”,在文本处理中有极大的特殊性,通常作为两个文字来对待。也是考虑到这种情况,目前在“默认”模式下后端程序在寻找光标前字符时会抓取至少两个文字的位置,并循环迭代(故而这种方式亦能正好解决“㘡{上甲}”一类的匹配)。而在“%”部件组合公式触发下,程序会以字符为单位进行匹配。故而在实际输入时,如需要获取“”一类字形时,可尽量向下拆分部件,比如“𡆥”可解构为“囗”、“卜”两个部件,故%卜犬亦可触发相应结果。 - 下拉提示菜单出现乱码文字: 这类情况也普遍地出现在
surrogate pairs上,如"𫡜"字,在输入后菜单里会显示“��{次}”的字样,或在辞条补全的情况下,“{殞}”会显示为��{殞},这种看似字符有误,但其实为预期效果。由于 monaco 底层 api 处理字符触发范围时会与输入字符范围保持一致(均为两个字符),故而渲染时,如"𫡜"等字 surrogate pair 的码点会被一分为二。而分割后的部分码点不符合 utf-8 的标准,所以显示为乱码。这种文字在 utf-8 编码的.json类型文件中也会有相似情况。但这些只是下拉菜单中暂时的渲染效果,如接受该提示后,编辑器内补全后的仍应为正常文字,所以不影响正常输入。
以上几个小问题是笔者测试时所能观察的一些情况。此外,由于数据结构、代码逻辑的复杂性以及原生 api 本身可能存在的各种程序 bug,工具也可能存在开发阶段中未能及时发现的一些额外问题,如遇到有类似情况,欢迎提供相应的反馈意见。
💻 实现原理
就使用专业的代码编辑器来开发古文字智能输入法的方法而言,本工具目前可见当属首例,其实现原理看似较为复杂,但实际上充分利用了monaco-editor强大的代码基础。但甲骨文作为独特的自然语言,其字形关系的复杂性、字头及部件编码的不稳定性以及相关数据结构的多样化都会导致许多未知的逻辑变数,对比一般编程语言如python、C、javascript、vue的文本处理有其特殊的编程上和学术上的挑战。如何根据语言背景的状况、学科已有的研究成果以及现实应用的可行性,来对具体编程逻辑做出即时调整,或根据编程进行自我调整,其实本身就是一个值得深入探讨的问题。本于这方面考虑,本小节会展示类似科研工具的制作方式,略微探讨如何利用 monaco 原生 api 函数的设计来适应语言的独特性,以达到工具适应语言,语言利用工具的目的。这其中某些具体的处理方案对金文、简帛文字等语言的分析和编辑器的实现当亦有一定的参考效果,希望借于此能对编程爱好者及数字人文工作者能有一定程度上的启发(本小节的说明将含有 javascript 相关的一些代码,并需要对网页前端的开发有相当的理解,如读者对此不感兴趣,可自行略过)。
首先,monaco-editor在前端环境下的安装和使用可参考monaco或github的官方说明,编辑器的使用需要在 javascript 和 node.js 的框架下才能运行(例如 vue、React 或 Angular.js)。 在没有兼容 js 的前端服务器可用的情况下,也可以直接使用monaco-playground提供的 demo 页面进行相对简单的语言测试。
注册自定义语言:
Monaco 编辑器默认支持的语言包括python、javascript、typescript、json、html、css等数十种编程语言,可以说范围十分广泛。但因为甲骨文作为自然语言,是不包含在已有编程语言定义中的。所以我们在 monaco 中,需要通过monaco.languages.register函数来注册自定义的语言,如下所示:
monaco.languages.register({ id: 'jiaguwen' })
这是指示 monaco 我们要使用一门新的自定义语言,但仅这样做并不能让编辑器知道这种语言相关的一些规则,所以我们还需要注册一些语法和辞条相关的内容。
定义语言语法:
定义好语言 id 后,我们可以选择为该语言定义一些语法规则,这样 monaco 就能知道如何对特定字符组成模式和组合进行高亮显示,比如[...]、{...}、<...>等,类似定义在setMonarchTokensProvider(lang_id, options)函数中进行:
monaco.languages.setMonarchTokensProvider('jiaguwen', {
ignoreCase: true,
unicode: true,
tokenizer: {
root: [
[/\{.*?\}/, 'tag'], // 高亮{貞}括号内的内容
[/\[.*?\]/, 'variable'], // 高亮[...]内的补全内容
[/[□|�]/, 'attribute.value'], // 还可以选择高亮缺位符
[/\s+/, 'whitespace'], // 空格一类的空字符,默认为不显示,也可以在monaco config中设置`renderWhitespace: ""all"`进行显示
],
},
})
经过以上初步设置后,即可有以下高亮效果(当然我们还可以自定义每个 token 具体使用什么颜色进行高亮):

以上tokenizer rule中是以正则表达式的方式来定义匹配字符,而所谓的语法”token”则可理解为自然语言中的语法成分、语法结构或语法规则,相关 token 的命名最好能够继承自 monaco 的默认主题(当然也可以完全自定义),可以选择的一些名称可参看vscode说明,但需注意 monaco 并不支持 vscode 工具全部的 token 体系,有些时候如果按照 vscode 的习惯来定义并不会对语法高亮产生任何效果,而且比较麻烦的是 monaco 官方的 docs 也未提供完整的 token 列表,不过笔者在反复测试后,发现以下的一些 token 可以对颜色高亮产生一定的效果:
const monacoTokenGroupA = [
'tag',
'metatag',
'keyword',
'tag.html', // html tags
'delimiter.html', // tag brackets
'metatag.content.html',
'tag.css',
'keyword.css',
'keyword.ts',
'keyword.js',
'keyword.flow',
'meta.scss',
'string.sql',
'strong',
'emphasis',
'keyword.field.marc',
]
const monacoTokenGroupB = [
'attribute.name',
'attribute.name.html',
'attribute.name.css',
'string.key.json',
'predefined.sql',
'delimiter.bracket.css',
'delimiter.bracket.ts',
'delimiter.bracket.js',
'class',
]
const monacoTokenGroupC = [
'attribute.value',
'attribute.value.html',
'attribute.value.xml',
'attribute.value.css',
'keyword.flow.scss',
'string',
'string.html',
'string.css',
'string.js',
'string.ts',
'string.value.json',
'delimiter.xml',
'attribute.value.subfield.marc',
]
const monacoTokenGroupD = [
'number',
'attribute.value.number',
'attribute.value.unit',
'number.hex',
'number.float',
'number.js',
'number.float.js',
'number.float.ts',
'number.hex.js',
'number.octal.js',
'number.binary.js',
'number.ts',
'attribute.value.hex.css',
'attribute.value.number.css',
'attribute.value.unit.css',
]
const monacoTokenGroupE = [
'type',
'variable',
'title',
'parameter',
'property',
'identifier.ts',
'identifier.js',
'tag.id.pug',
'tag.class.pug',
'type.identifier.ts',
'string.yaml',
'keyword.json',
]
const monacoTokenGroupF = [
'constant',
'regexp',
'member',
'punctuation',
'metatag.html', // IDoctype
'metatag.xml',
'metatag.php',
'delimiter.parenthesis.ts',
'delimiter.parenthesis.js',
'delimiter',
'delimiter.js',
'delimiter.ts',
'operator',
'operator.scss',
'operator.sql',
'operator.swift',
'punctuation.backslash.marc',
]
以上不同group是按照笔者自己的习惯对相似的 token 类型进行的归类,一个 group 里推荐使用相同的高亮颜色,设置较少的 token group 可以避免颜色过多。当然这其中也不并是所有 token 都会派上用场,很多设置都是 language-specific 的,只有在js、sql或html里才会生效。像甲骨文这种自然语言,大概设置十个左右的 token 类型来涵盖特殊的文本内容(如缺位符、方向符、补全括号、隶定括号)就足够使用了,名称也可以从上述列表中随机挑选。过多的颜色设置会导致编辑器的视觉效果过于花哨,不利于长时间的编辑。
辞条补全: monaco辞条补全的功能大概才是我们所希望重点关注的部分(官方 demo提供了一个json语言相关的简单辞条补全)。甲骨文语言体系虽然复杂,但也可以按照类似方式来完成,其实我们只需要预先定义好一个文本如.txt、.json、csv,输入含有任何类型的甲骨辞句,如定义干支甲子、乙丑、丙寅、丁卯、戊辰等六十个辞条,导入为 js 变量类型,再进行以下简单处理,即可实现简单的补全功能。
// 从.txt、.csv文件中导入数据
const wordTriggers = ['甲子', '乙丑', '丙寅', '丁卯', '戊辰', '己巳', '庚午', ..., '壬戌', '癸亥']
monaco.languages.registerCompletionItemProvider('jiaguwen', {
provideCompletionItems: function (model, position) {
// range定义了要匹配的文本范围,可以根据需要来定义一个字、一句话或者整个文本段落来作为补全的触发内容,但这里我们只需要光标前最后一个字即可
const range = {
startLineNumber: position.lineNumber,
endLineNumber: position.lineNumber,
startColumn: Math.max(1, position.column - 1),
endColumn: position.column,
}
const lastChar = model.getValueInRange(range)
// 接收预先定义好的辞条词条,然后使用列表循环的方式来过滤任何含有最后一个字符的词条,这样比如最后一个字符为“癸”字,那么“癸亥”、“癸酉”等词条就会被过滤出来
const wordSuggestions = wordTriggers
.filter((str) => str.includes(lastChar)) // if contain targeted character
.map((item) => {
return {
filterText: lastChar, // 触发字符
label: item, // 下拉菜单的标签提示
kind: monaco.languages.CompletionItemKind.Text,
insertText: item, // 文本替换
detail: '辞典词条', // 下拉菜单右侧的类型标签
range: range,
}
})
return {
suggestions: wordSuggestions,
}
},
})
经过以上简单的代码,我们就可以得到以下效果:

很明显,以上只是用到了最基础的处理逻辑,即用一个一维的数组,遍历列表中的每个词语,如果当前词语含有光标前的最后一个字符,那么就认为是匹配,再把词语以 monaco 所接受的数据类型(ICompletionItem)返回作为补全意见。但就算是基础的逻辑,假如我们数据量足够大,比如如果能像甲骨文词谱、殷墟甲骨学大辞典那样收集所有常用的甲骨学词汇和语句,这种情况下的文本补全也能实现非常惊艳的效果。
当然一维数组只适用于辞条较少的情况,在辞条较多的情况,我们希望能够给用户更多的辞条提示(比如利用detailproperty 来提示当前辞条为“干支”、“人名”、“祭名”等),或者我们需要根据文本语境提供更多的筛选条件,以免返回太多无关的结果,这在辞条很多的情况下尤其重要。再或者,我们希望能够在插入替换文本后,进行更多的文本操作,例如语法检查、文本格式化、AI补全的功能,也是可以利用相关代码逻辑来触发的。此外,我们可能还希望提高编辑器的计算性能,防止出现延迟和卡顿,还可以考虑使用trie树或字典树更高级的数据类型来进行更高效的匹配。
特殊字符触发替代模式: 如果希望进行略微复杂的操作,比如像本页面编辑器那样使用@、%来触发不同的输入模式,也是绝对可行的。而在实际应用当中,这种处理方式可以说也是十分必要的,我们希望能把不同的功能进行分割式的处理,而不是一股脑地全部混在一个同一文件或列表当中,否则可能提示结果过多,也不利于数据的维护和更新。同时,不同的补全也需要会要求不同的数据类型。比如严{宽}式的补全就不可以像上面那样使用一维的数组,我们需要额外的标签来告诉我们哪些是宽式,哪些是严式,哪些是拼音等等。例如我们可以采用dict (python)或Object (js)的数据类型:
{
严式: '𢦏',
宽式: '災',
简体: '灾',
拼音: 'zai',
替代写法: '𢦏{災}',
类型: '名词',
}
这样在计算字符是否匹配时,可以检查严式、宽式或拼音等的属性里是否含有该字符或该拼音字串,如果有那就以严式{宽式}的格式来返回,或返回任何自定义的数据。
当然这是最理想状况下的数据储存方法,我们还可以定义更多的属性例如甚至于释文举例、著录来源。但在实际应用时,我们会发现,这样精细的数据结构似乎是一个 overkill,很多提示方法我们会想以其他功能或者工具来替代(比如超链接到其他页面)。在一般情况下,我们也会想尽量节省网站内存,而 monaco 本身的代码和其自带的web worker已经占用了~60MB-90MB+,所以不宜再加载体量过大的数据。编辑器本身只是一个语言处理器,其目的是帮助到文字的输入和写作。而如果只是想实现一个拼音输入、繁简替换、子字头替换输入法,也用不到太复杂的数据结构(比如无需用 object 或字典的方式来标注每个数据的类型),毕竟我们匹配逻辑很简单,只要一个数据 entry 中含有某一字符,那么该 entry 中所有的数据都是相关的。那么以上提到的三个功能甚至用同一个逻辑就可以实现。以“隻”字为例,我们可以定义如下,来包含所有与“隻”相关的替代写法和拼音:
['㸕', '獲', '隻', '获', '只', 'zhi', 'huo', 'jue']
在 monaco 的provideCompletionItems函数中,我们可以使用以下逻辑来实现:
const triggers = [['㸕', '獲', '隻', '获', '只', 'zhi', 'huo', 'jue'], ["災","𢦏", "𢦔", "灾", "zai"], ...]
monaco.languages.registerCompletionItemProvider('jiaguwen', {
triggerCharacters: ['@'],
provideCompletionItems: function (model, position) {
// @ 激活特殊模式
let alternateSuggestions = []
const lineUntilPosition = model.getValueInRange({
startLineNumber: position.lineNumber,
startColumn: 1,
endLineNumber: position.lineNumber,
endColumn: position.column,
})
// 只检测@符号后的文本
let regex = /@[^0-9]+$/
let match = lineUntilPosition.match(regex)
if (match) {
const matchedText = match[0].substring(1)
const range = {
startLineNumber: position.lineNumber,
endLineNumber: position.lineNumber,
startColumn: position.column - matchedText.length - 1,
endColumn: position.column,
}
let alternateSuggestionsArray = triggers.filter((item) =>
item.includes(matchedText),
)
for (let i = 0; i < alternateSuggestionsArray.length; i++) {
let arr = alternateSuggestionsArray[i]
for (let j = 0; j < arr.length; j++) {
if (arr[j] === matchedText) continue
if (arr[j].match(/[a-zA-Z]/) && arr[j].length > 1) continue
const entry = {
filterText: '@' + matchedText,
label: arr[j],
kind: monaco.languages.CompletionItemKind.Text,
insertText: arr[j],
detail: '替代写法',
range: range,
}
if (alternateSuggestions.find((item) => item.label === entry.label))
continue
alternateSuggestions.push(entry)
}
}
return {
suggestions: [...alternateSuggestions],
}
}
}}
即遍历数组中的每个数组,如果数组中含有目前文字,那么就是匹配成功,就可以丢弃其他无关的数组,只在匹配到的数组中遍历每个文字(或辞条),作为返回提示,最终我们可以得到以下效果:

这种处理逻辑下,无论是“@隻”、“@獲”、“@只”、“@zhi”、“@huo”的字符都可以触发其他任何的替代写法,这样我们就避免了过于复杂的代码逻辑和数据结构,同时也能够实现较为全能的输入模式。此外,在数据预处理和生成上,我们也无需对所有可能的文字拼音和繁简体组合进行一一的数据标注,当前甲骨文中存在的各种隶定超过 4000 多条,如果每一条都要进行详细的数据标注,那么数据量将会非常庞大,会非常浪费人力标注的资源。且以后如果隶定对应的关系发生了变化,我们还要进行各种一对一的修改,非常不利于数据的完整性和可维护性。实际上,在数据准备过程中我们可以使用python进行自动的繁简转换和拼音生成。如 python 生态中OpenCC和pypinyin的库就可以很好的做到这一点:
import opencc
from pypinyin import pinyin, Style, lazy_pinyin
simple2trad = opencc.OpenCC("s2t.json") # 简体转繁体
trad2simple = opencc.OpenCC("t2s.json") # 繁体转简体
simple2trad.convert("只") # 返回“隻”
trad2simple.convert("隻") # 返回“只”
lazy_pinyin("只") # 返回“zhi”
pinyin("只", style=Style.TONE3) # 返回“zhi3”
这种情况下,我们其实只需要一张隶定表,然后通过 python 脚本自动化生成所有繁简体和拼音的组合即可。这样就只需要定义甲骨的隶定关系即可。隶定表格的例子可以如下:
| 甲骨字 | 隶定 | 隶定类型 |
|---|---|---|
| ... | 隻 | 严式 |
| ... | 獲 | 宽式 |
| ... | 鼎 | 严式 |
| ... | 貞 | 宽式 |
这样我们就避免了很多繁琐的工作。遇到部分非 CJK 的文字,我们再用单独的表格添加一些辅助数据即可。这样就最大程度地做到了数据的自动化处理,减少了很多的人为标注的工作量。
那么如果像是鼎{貞}这种宽式和严式的对应关系的补全,我们也可以用上述类似的方法定义completionItem,相关数据类型的选择可以有多种:
[
{
严式: ['隻'],
宽式: ['獲'],
},
{
严式: ['𤑔', '爇', '烄', '𤆰'],
宽式: ['焚'],
}
]
// ------ or -------
[
[['隻'], ['獲']],
[['𤑔', '爇', '烄', '𤆰'], ['焚']],
]
即可以使用字典的集合,或者多维数组。再如,如果需要进行部件组合式的补全,那么数据类型可以如此定义:
const components = [
{
虐: [['匕', '虎']],
},
{
'𣈉': [
['尗', '暈', '又'],
['尗', '日', '丶', '又'],
],
},
]
以上因为一个字形可能有多种部件组合的定义,即可以用二维的数组来定义,这样可以提供更多的补全支持。这样综合上述类型,如果想要复现编辑器里的三大输入模式,完整的代码示例可以用如下解决:
const alternateTriggers = [
['㸕', '獲', '隻', '获', '只', 'zhi', 'huo', 'jue'],
['災', '𢦏', '𢦔', '灾', 'zai'],
]
const componentTriggers = [
{
虐: [['匕', '虎']],
},
{
'𣈉': [
['尗', '暈', '又'],
['尗', '日', '丶', '又'],
],
},
]
const looseStrictTriggers = [
[['隻'], ['獲']],
[['𤑔', '爇', '烄', '𤆰'], ['焚']],
]
const wordTriggers = [
'甲子',
'乙丑',
'丙寅',
'丁卯',
'戊辰',
'己巳',
'庚午',
'壬戌',
'癸亥',
]
monaco.languages.registerCompletionItemProvider('jiaguwen', {
triggerCharacters: ['@', '%'], // 两种特殊触发字符
provideCompletionItems: function (model, position) {
// @ 模式
let alternateSuggestions = []
const lineUntilPosition = model.getValueInRange({
startLineNumber: position.lineNumber,
startColumn: 1,
endLineNumber: position.lineNumber,
endColumn: position.column,
})
let regex = /@[^0-9]+$/
let match = lineUntilPosition.match(regex)
if (match) {
const matchedText = match[0].substring(1)
const range = {
startLineNumber: position.lineNumber,
endLineNumber: position.lineNumber,
startColumn: position.column - matchedText.length - 1,
endColumn: position.column,
}
let alternateSuggestionsArray = alternateTriggers.filter((item) =>
item.includes(matchedText),
)
for (let i = 0; i < alternateSuggestionsArray.length; i++) {
let arr = alternateSuggestionsArray[i]
for (let j = 0; j < arr.length; j++) {
if (arr[j] === matchedText) continue
if (arr[j].match(/[a-zA-Z]/) && arr[j].length > 1) continue
const entry = {
filterText: '@' + matchedText,
label: arr[j],
kind: monaco.languages.CompletionItemKind.Text,
insertText: arr[j],
detail: '替代写法',
range: range,
}
if (alternateSuggestions.find((item) => item.label === entry.label))
continue
alternateSuggestions.push(entry)
}
}
return {
suggestions: [...alternateSuggestions],
}
}
// % 模式
const componentSuggestions = []
regex = /%[^0-9]+$/
match = lineUntilPosition.match(regex)
if (match) {
const matchedText = match[0].substring(1)
const range = {
startLineNumber: position.lineNumber,
endLineNumber: position.lineNumber,
startColumn: position.column - matchedText.length - 1,
endColumn: position.column,
}
// 定义一个临时函数来判断一个数组是否为另一个数组的子集
function isSubset(subset, main) {
const mainFreq = main.reduce((acc, val) => {
acc[val] = (acc[val] || 0) + 1
return acc
}, {})
for (const element of subset) {
if (!mainFreq[element]) {
return false
}
mainFreq[element]--
}
return true
}
const textSplit = matchedText.split('')
let componentSuggestionsArray = componentTriggers.filter(
(item) =>
Object.values(item)[0].filter((arr) => isSubset(textSplit, arr))
.length > 0,
)
for (let i = 0; i < componentSuggestionsArray.length; i++) {
let obj = componentSuggestionsArray[i]
const key = Object.keys(obj)[0]
const entry = {
filterText: '%' + matchedText,
label: key,
kind: monaco.languages.CompletionItemKind.Text,
insertText: key,
detail: '部件构字',
range: range,
}
if (componentSuggestions.find((item) => item.label === entry.label))
continue
componentSuggestions.push(entry)
}
return {
suggestions: [...componentSuggestions],
}
}
// 默认输入模式,即没有@、%特殊字符触发时
let finalPairSuggestions = []
let finalWordSuggestions = []
// 这一处我们就需要考虑到`surrogate pair`存在的可能,所以我们需要定位光标前的两个字符位置,再进行反向字符切割
for (let i = 1; i <= 2; i++) {
const range = {
startLineNumber: position.lineNumber,
endLineNumber: position.lineNumber,
startColumn: Math.max(1, position.column - i),
endColumn: position.column,
}
const lastChar = model.getValueInRange(range)
let pairSuggestions = looseStrictTriggers.filter(
(twoSegArr) =>
twoSegArr[0].includes(lastChar) || twoSegArr[1].includes(lastChar),
)
if (pairSuggestions.length > 0) {
let suggests = []
for (let i = 0; i < pairSuggestions.length; i++) {
let pair = pairSuggestions[i]
const stricts = pair[0]
const looses = pair[1]
// map each strict-loose pair
for (let j = 0; j < stricts.length; j++) {
for (let k = 0; k < looses.length; k++) {
const entry = {
filterText: lastChar,
label: `${stricts[j]}{${looses[k]}}`,
kind: monaco.languages.CompletionItemKind.Text,
insertText: `${stricts[j]}{${looses[k]}}`,
detail: '宽严式对应',
range: range,
}
if (
finalPairSuggestions.find((item) => item.label === entry.label)
)
continue
suggests.push(entry)
}
}
}
finalPairSuggestions.push(...suggests)
}
// 基于词语的补全
const wordSuggestions = wordTriggers
.filter((str) => str.includes(lastChar))
.map((item) => {
return {
filterText: lastChar,
label: item,
kind: monaco.languages.CompletionItemKind.Text,
insertText: item,
detail: '辞典词条',
range: range,
}
})
finalWordSuggestions.push(...wordSuggestions)
}
// 除重或排序(可选)
finalPairSuggestions = Array.from(
new Set(finalPairSuggestions.map((a) => a.label)),
).map((label) => {
return finalPairSuggestions.find((a) => a.label === label)
})
finalWordSuggestions = Array.from(
new Set(finalWordSuggestions.map((a) => a.label)),
).map((label) => {
return finalWordSuggestions.find((a) => a.label === label)
})
return {
suggestions: [...finalPairSuggestions, ...finalWordSuggestions],
}
},
})
以上代码的完整版也已放到了monaco-playground编辑器的 demo,感兴趣的师友可以在这里进行查看、测试和修改。
这样做到的几项辞条补全功能基本已能兼顾到甲骨文中字形输入和释文制作的大部分需求,亦即“找字”和“补字”两种,再加上“常用辞条”的辅助,释文输入的速度就可以获得很大程度上的效率提升,而这也是monaco-editor对古文字领域最大的帮助。此外,在未来,我们还可以考虑加入code snippets的功能,比如释文补全或者释文模板,不过这是建立在有着完整释文数据库上基础上才能做到的,就当前的情况来看,暂时还没有实现的可能性。
其次,除了语法高亮和辞条补全两种,我们还可能对 monaco悬浮提示的功能感兴趣。这种功能通过观察编辑器界面内发生的鼠标悬浮效果来触发 callback 函数,通过自定义处理方法,我们可以实现不需要离开页面的数据查询和快捷访问。比如,我们可以在用户的鼠标悬浮在某个文字上时,根据文字内容,来显示该字形的释文、音韵、字形、字体等信息。这样可以帮助用户更好地理解和使用这个字形,而无需再去字库检索页面再进行查看,也就节省了额外的操作。这种在 monaco 中也是有支持的,只需要在registerHoverProvider()中定义一个处理函数,再利用相关 api 导向数据库即可。
首先,定义数据查询的函数,这里示例使用了vue.js框架下的两个常用库,但其他任何类型的data fetching逻辑也可以做到类似效果,比如 js 原生的fetch()函数和 lodash 的_.debounce()等等:
import axios from 'axios'
import { useDebounceFn } from '@vueuse/core'
const debouncedServerLookUp = useDebounceFn((text) => {
return axios
.get('/fetch-data-from-server/', {
params: {
name: text,
},
})
.then(async (res) => {
return res?.data ?? {}
})
.catch((err) => {
throw new Error(err)
})
}, 3000)
数据的查询当然也需要一个后端和 sql 数据库的支持,想要完整实现这个功能,是需要对全栈开发有相当的了解才可以的。在这里,我们只是简单的模拟了一个基础数据查询的过程,我们通过axios库来对后端发送一个GET请求,然后通过useDebounceFn来限制请求的频率,这样可以避免用户在快速移动鼠标时频繁的请求,而导致服务器压力过大。
接下来,我们把数据查询的逻辑集成到相关的 callback 函数中,这样当用户悬浮在某个文字上时,就会触发这个数据访问的端点,然后进行数据查询,最后返回数据:
monaco.languages.registerHoverProvider('jiaguwen', {
provideHover: function (model, position) {
const range = new monaco.Range(
position.lineNumber,
position.column,
position.lineNumber,
position.column + 1,
)
const text = model.getValueInRange(range)
// 如果是数字、字母或者特殊符号如标点,则无需进行查询
if (text.match(/[a-zA-Z0-9.,。:;“”‘’??!!\-\=\[\]\{\}\\\|]/)) return
// 数据库查询
return debouncedServerLookUp(text)
.then((res) => {
return {
range: new monaco.Range(
position.lineNumber,
position.column,
position.lineNumber,
position.column + 1,
),
contents: [
{
value: `# 字形信息 - ${text}`,
},
{
value: `### 字库链接: [link](${fill_url_here}/glyphs/${res.字头})`,
},
{
value: `### 严式隶定: ${res.严式隶定 ?? ''}`,
},
{
value: `### 宽式隶定: ${res.宽式隶定 ?? ''}`,
},
{
value: `### 隶定拼音: ${res.隶定拼音 ?? ''}`,
},
// ...其他数据
],
}
})
.catch((err) => {
return
})
},
})
以上就是悬浮提示实现的全过程。其编程难度并不很高,在功能上而言,其实也不如辞条补全那么独特。一般来说,就算离开了 monaco 的编辑器环境,现代网页端下的任何普通页面也都是可以观察用户鼠标点击、移动和悬浮的情况的,所以只要想实现,是可以将类似功能集成到任何一个网页中的,故而在这里只是作为一个辅助性的功能而已。我们更关注的,还是在于键鼠事件发生后的处理函数,即以何种信息来提高用户的输入效率和体验。一种思考是,在将来数据量提高后,我们可以利用专门训练的AI语言模型来分析用户悬浮到的文字段落,然后给出更加智能的段落解释,这样实际上就是一个实时的AI翻译功能了。
最后,Monaco 还有提供其他一些类型的函数,在本次工具制作中由于相关数据或应用场景不足,并没有得到太多的关注和集中开发,不过随着学科内的知识积累和技术革新,以后在古文字领域当也有一定的利用价值,以下就略微论述一下:
- Diff Editor: 双文本并行编辑器。即在同一页面中设置两个编辑器,输入相似内容后,可以高亮文本行不一致的地方,如两者在文字的增删、修改上的异同。如下所示:

这种在古文字领域的应用场景最可能是在对比两个版本的释文时,可以直观地看到两个版本的差异。比如在制作某著录的释文时,可以直接在编辑器中放入以前合集或摹系的释文内容,然后通过对比新旧版本的差异,以便于更好地进行校对和修改。但这需要各个著录都有着一个完整的释文数据库,且使用相同的字符/字体显示,才可以有应用的可能。就目前各家释文“贴图”状况来看,这种功能的应用范围当属有限。 - 行内词语注释: 即在编辑器中对某个词语进行灰色的文字标注,这种在编程语言中主要是对一般变量类型和参数类型进行标注,笔者在进行开发过程中也会偶尔用到,相关函数能根据后台文档实时提示语法和参数信息。这种在古文字中还是有一定的应用场景的。尤其是
语法成分的标注显示,比如甲骨的“前辞”、“占辞”和“验辞”,是可以根据对段落内容的分析进行实时生成的,如下所示:
这种功能可以帮助解析古文字语句的语法结构,但这种功能的实现需要建立一种完整的语法分析逻辑和体系,而这种体系的构建也是要求对古文字材料相当深入的了解和研究的,并且也要有足够材料支撑。而且就自然语言来看,似乎基于 AI 的语法分析模型将要比任何复杂的传统算法更为有效。 - 符号查找和高亮: 这一功能与上述的“行内注释”具有相当类似的特点,也是对
语法成分进行符号化级别的解析和标注,但不同的是上述是注释性的,而符号查找则除了注释,还可以提供非常强大的查询和高亮效果。比如在编辑器内给定一个长文本,我们可以根据预先定义好的标签或分析算法来对每个词语、或每个文字做出定义,比如判断哪些是人名、族名、方国名,哪些又是主语、谓语和宾语,用户还可以根据符号来高亮所有类似的语法成分,如下所示: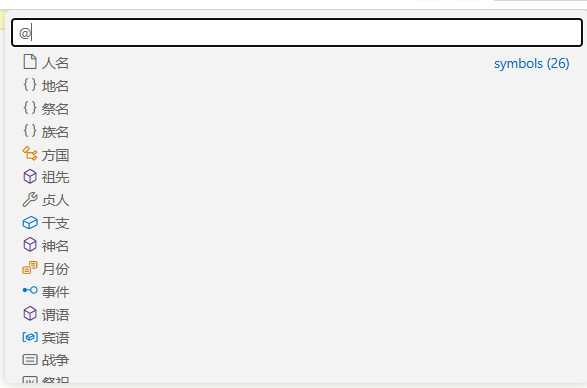
所谓符号化级别的查找,即不是根据特定词语进行的检索,而是一类近似事物的查找。比如贞人名,则会有殻、賓、爭、扶等等贞人,而通常以“殻貞”、“賓貞”的形式出现,不限于一个词语和句式。再比如“一”、“二”、“三”、“四”的兆序则以“一。”、“二。”的格式出现在释文中,数字也不只有一个。那么我们就可以针对类似内容进行标签化的定义。通常类似的功能似乎常见于一个预标注的数据库中,我们邀请专家和学者来对数据库中一字一句做出标注和诠释。但不同的是,在 monaco 编辑器的环境下,其功能是可以进行实时演算,所以能适用于自定义文本和数据集的分析,但这样也要求我们对语言材料做出自动化的编程分析。但相对而言,如果仅是基础字符级标注,那么我们通过对镜原甲骨字库的系统标注(比如专名标注),就已经可以部分地实现非常强大的符号化分析的功能了。而这一点也会是接下来要完成的主要工作之一。诸如其他的一些小功能,还有语法错误高亮、文本折叠、文本格式化等等,这些在一般编程语言中都会有不同程度上的广泛应用,但就并不太能适用于当前学科领域了。
以上就是笔者对于 monaco-editor 的一些简单的使用和实践,希望能对大家有所帮助。鉴于当前实现的方法和功能受于数据的限制,故而只能作为一些临时的功能来对待,当前在甲骨学严重缺乏统一释文数据库、词汇库、字形库、文字考释库、字体的情况下,我们只能通过一些基于个人的数据收集和整理来填充一些技术空白,这制作期间数据收集不易,也难免会受到个人知识和能力的限制,肯定会有很多处理上的不合理之处,这还要在未来较长时间来进行不断的完善和更新。